RAG项目总结V1.0
项目地址
GitHub地址:
Chunfei-He/MyRAG (github.com)
项目进度
数据处理pipeline done
目前数据源:项目README.md文件、阿里2023财报.pdf、斗破苍穹小说.txt、iPhone使用手册(ios5).pdf、中华人民共和国消费者权益保护法.pdf
实现功能:搭建web demo页面可针对上述文件提问,对于没有相关信息的问题可以拒绝回复。

存在问题:
- iPhone使用手册版本较旧,缺少iPad使用手册。未考虑同一问题(如:如何拍照)可能来自两种设备持有者的情况
- 阿里财报为繁体,导致回复时出现部分繁体字

后续升级技术方案:
- 针对问题一,计划在向量相似度计算之前加入router组件,先判断需要调用哪个向量库,再进行针对性调用
- 针对问题二,修改prompt模板,强调使用简体中文回复
- 待实现功能有:定义金融指标,利用财报数据计算。计划加到router组件中,判断是否需要使用数据查询功能(直接从表格中查询数据,而不是计算相似度)
- 可升级方向有:
- 目前只从数据库中召回相似度排名top 1的数据作为上下文,后续可以优化召回内容,比如召回多条、多次问答再总结
- 对于markdown这种结构化语言,包括使用手册这种每一块有明确主题的文档,可以使用标题作为检索key
- 可以考虑加入召回后排序
项目架构
component是RAG的组件,分为四大部分(数据切分,向量化,向量存储,大模型)
data用于存放需要嵌入的文件(兼容Pdf TXT,md文件)
db用于存放向量化后的数据,也是数据库的加载路径
build.ipynb构建向量数据库
webdemo_by_gradio使用gradio基于嵌入的文件调用OpenAI的回答助手
1 | |
什么是RAG?
检索增强生成(RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。
它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型(LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
为什么需要RAG?
LLM会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为 AI 时代的一大趋势。
RAG 通过在语言模型生成答案之前,先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程,极大地提升了内容的准确性和相关性。RAG 有效地缓解了幻觉问题,提高了知识更新的速度,并增强了内容生成的可追溯性,使得大型语言模型在实际应用中变得更加实用和可信。
RAG的基本结构有哪些呢?
- 要有一个向量化模块,用来将文档片段向量化。
- 要有一个文档加载和切分的模块,用来加载文档并切分成文档片段。
- 要有一个数据库来存放文档片段和对应的向量表示。
- 要有一个检索模块,用来根据 Query (问题)检索相关的文档片段。
- 要有一个大模型模块,用来根据检索出来的文档回答用户的问题。
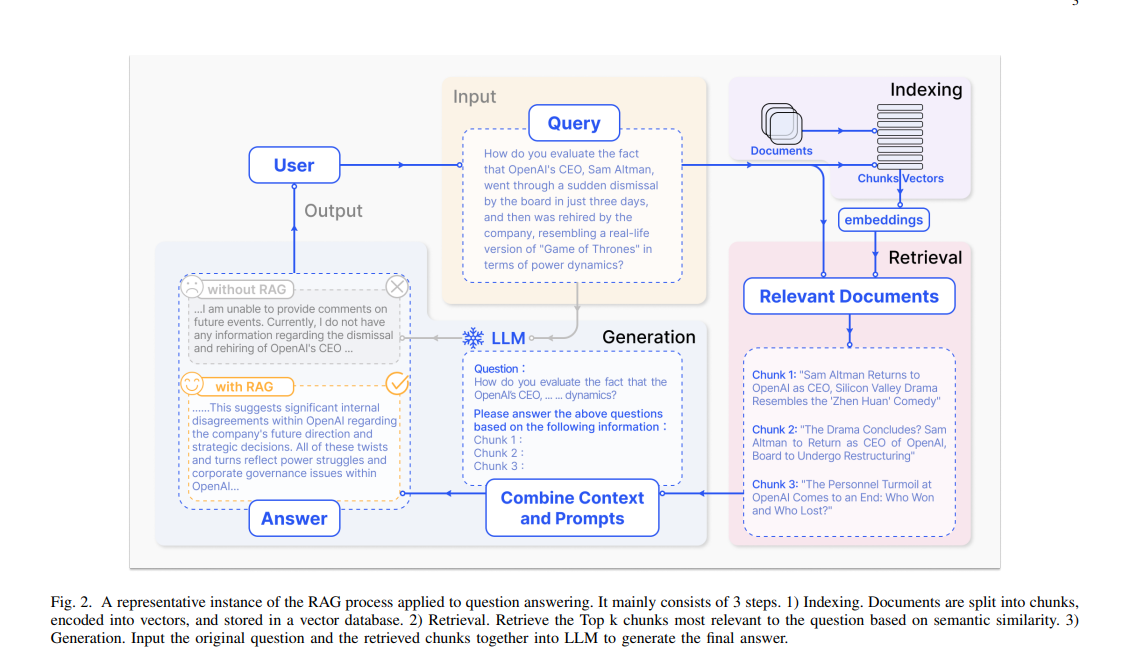
参考下图,RAG的基本流程有:
- 索引:将文档库分割成较短的 Chunk,并通过编码器构建向量索引。
- 检索:根据问题和 chunks 的相似度检索相关文档片段。
- 生成:以检索到的上下文为条件,生成问题的回答。
向量化
向量化的类主要是用来将文档片段向量化,将一段文本映射为一个向量。
get_embedding方法:获取文本的向量表示cosine_similarity方法:计算两个向量之间的余弦相似度
文档加载和切分
类主要是用来加载文档并切分成文档片段。这个文档可以是一篇文章,一本书,一段对话,一段代码等等。这个文档的内容可以是任何的,只要是文本就行。比如:pdf文件、md文件、txt文件等等。
1 | |
按 Token 的长度来切分文档,可以设置一个最大的 Token 长度,然后根据这个最大的 Token 长度来切分文档。这样切分出来的文档片段就是一个一个的差不多相同长度的文档片段了。
在切分的时候要注意,片段与片段之间最好要有一些重叠的内容,这样才能保证检索的时候能够检索到相关的文档片段。还有就是切分文档的时候最好以句子为单位,也就是按 \n 进行粗切分,这样可以基本保证句子内容是完整的。
数据库&&向量检索
设计一个向量数据库用来存放文档片段和对应的向量表示了。
设计一个检索模块,用来根据 Query (问题)检索相关的文档片段。
persist:数据库持久化,本地保存load_vector:从本地加载数据库get_vector:获得文档的向量表示query:根据问题检索相关的文档片段query方法具体实现:
首先先把用户提出的问题向量化,然后去数据库中检索相关的文档片段,最后返回检索到的文档片段。
大模型
根据检索出来的文档回答用户的问题。