LoRA原理
LORA 是一种低资源微调大模型方法,出自论文 LoRA: Low-Rank Adaptation of Large Language Models。 使用 LORA,训练参数仅为整体参数的万分之一、GPU 显存使用量减少 2/3 且不会引入额外的推理耗时。
高效微调(PEFT)的基本原理
full fine-tuning:在微调过程中模型加载预训练参数进行初始化,并通过最大化语言模型概率进行参数更新,这种微调方式的主要缺点是我们学习到的参数增量的维度和预训练参数是一致的,需要的资源较多。
高效微调方法则通过选择性地调整少量参数或增加额外的小型模块来显著降低训练成本,同时保持良好的模型性能。
LoRA实现方式
Instrisic Dimension
- 为何用数千的样本就能将一个数十亿参数的模型微调得比较好?
- 为何大模型表现出很好的 few-shot 能力?
https://arxiv.org/abs/2012.13255?utm_source=chatgpt.com
Aghajanyan 的研究表明:预训练模型拥有极小的内在维度 (instrisic dimension),即存在一个极低维度的参数,微调它和在全参数空间中微调能起到相同的效果。同时 Aghajanyan 发现在预训练后,越大的模型有越小的内在维度,这也解释了为何大模型都拥有很好的 few-shot 能力。
LoRA
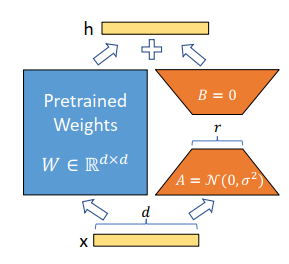
LoRA(Low-Rank Adaptation of Large Language Models) 的实现核心是通过 低秩矩阵分解 来对模型权重进行高效微调,而不需要更新模型的全部参数。
LoRA 假设模型的权重矩阵在微调过程中只需要少量的调整。
因此,可以将模型权重表示为:
在训练过程中,低秩的适应矩阵ΔW仅仅放大了对下游任务有用的特征,而不是预训练模型中的主要特征。
在初始化时,A使用高斯初始化,B使用零矩阵进行的初始化。因为 通常是一个非常小的值(实验证明1,2,4,8的效果就非常好),所以LoRA在训练时引入的参数量是非常小的,因此它的训练也是非常高效的,也不会带来显著的显存增加。
LoRA要求 或者 其中之一必须使用零矩阵进行初始化,这样当数据第一次通过网络时,它和预训练的结果是一致的,这样便保证了模型在初始阶段便有一个不错的效果。苏剑林老师指出,这种一个全零,一个非全零的方式带来了不对称的问题[3],其实我们也可以使用两个非全零矩阵进行初始化,但是需要事先将预训练权重减去初始化的值。
LoRA原理
https://chunfei-he.github.io/2024/09/22/LoRA原理/