Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers

https://github.com/meta-recsys/generative-recommenders
1. challenges
- 特征缺乏统一的结构描述: 推荐系统中的特征是异质的, 缺乏明确一致的结构描述, 比如交叉特征, 高基数id特征, 计数特征, 比率特征等, 这些特征有些是sparse的, 有些是dense的。
- 物料池规模大&动态变化: 推荐系统中物料池经常是数以亿计的, 且物料池动态变化, 不像NLP那样只有相对静态的几十万量级词汇量, 这使得推荐系统训练和推理的开销都很高。
- 计算成本高是大规模序列模型落地的主要瓶颈: 推荐系统每天需要处理的token比GPT-3在1-2个月内处理的token还要多上几个数量级。
2. 生成式推荐
2.1 Unifying heterogeneous feature spaces in DLRMs
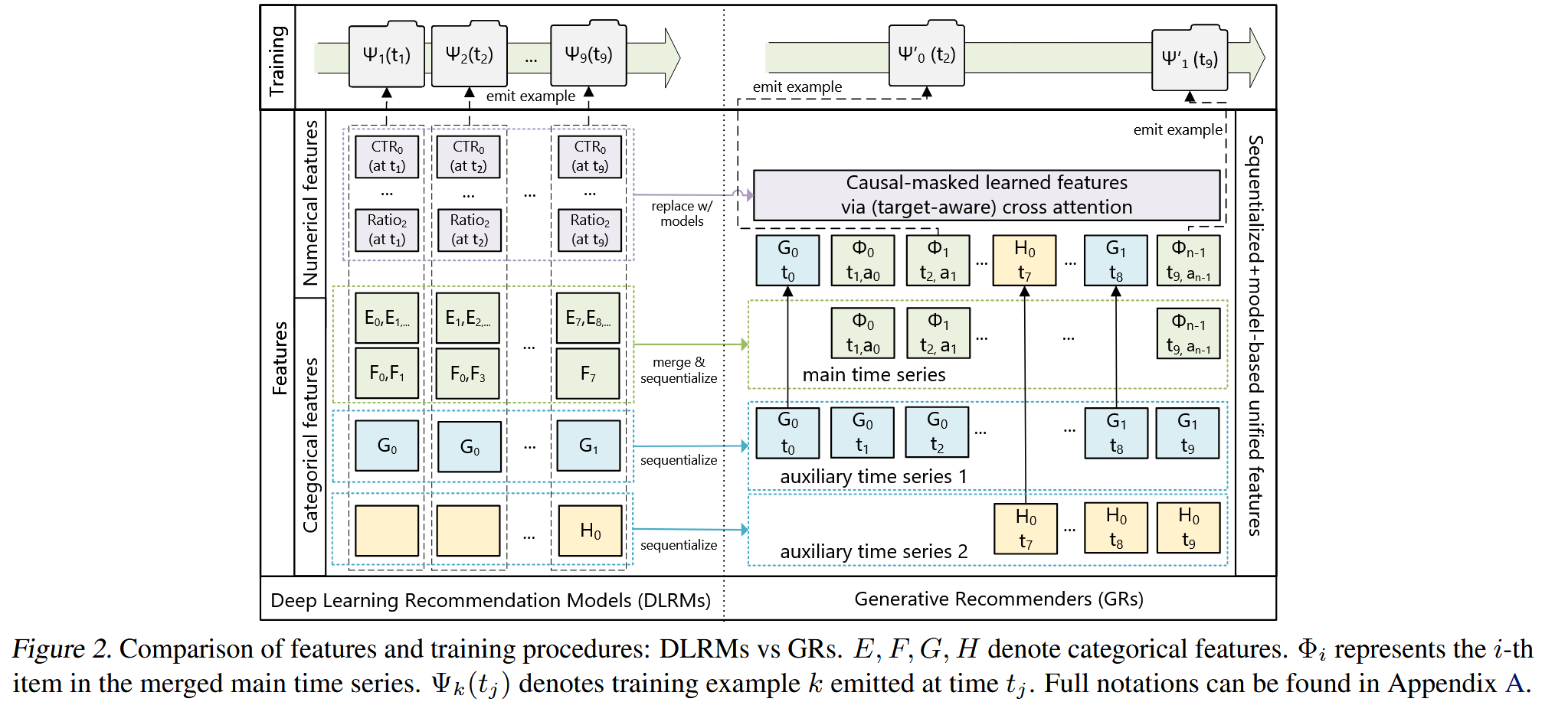
Categotical (‘sparse’) features
比如用户收藏的item序列, 用户关注的作者ID, 人口统计信息等。
- 时序化(sequentialize)
- 先找出最长的时间序列,通常是用户和物品交互的记录(比如点击、点赞等),作为主时间序列。
- 其它特征(比如人口统计信息、关注的创作者等)通常变化比较慢,也以时间序列的形式存在。
- 压缩(compress)
- 对于这些变化缓慢的时间序列,不保留每一次记录,而是在每个连续时间段中只保留最早的那一个值。
- 这样压缩后,把这些信息合并到主时间序列中
Numerical (‘dense’) features
舍弃:更新频繁
2.2 序列直推式任务:重塑召回与排序


召回:模型学习分布
目标是从候选集 X_c 中选出能最大化 reward 的物品: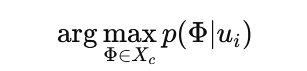
排序:
- 工业级推荐排序通常是 target-aware:排序时需要立刻考虑目标物品 Φᵢ₊₁ 与历史的交互关系。
- 标准自回归做不到这一点,因为它往往在编码结束后才进行交互(比如 softmax)。
- 论文的方法:交错(interleaving) 物品和行为,让 Φ 和 a 交替出现。
2.3 生成式训练
3 HSTU:新的Self-Attention Encoder
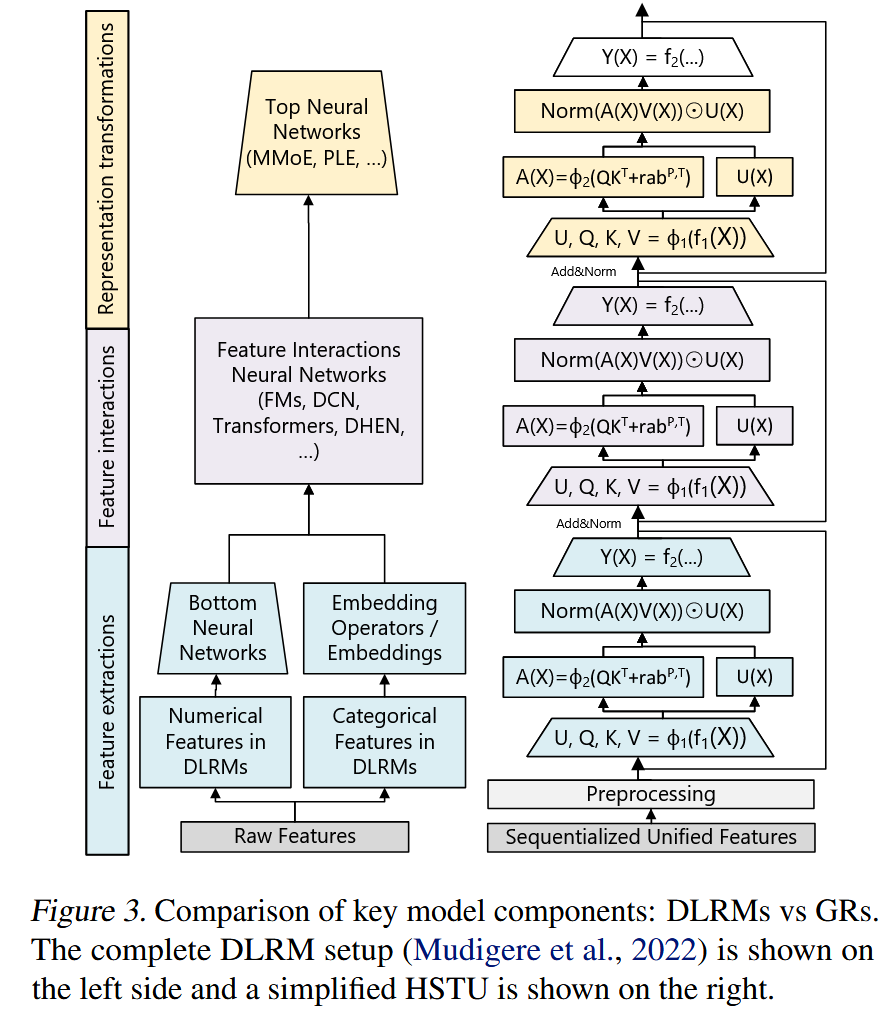
HSTU由残差连接的层堆叠而成。每一层包含3个子层, 分别是Pointwise Projection(1)、Spatial Aggregation(2)、Pointwise Transformation(3)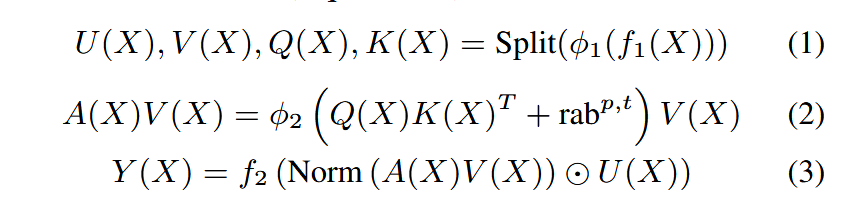
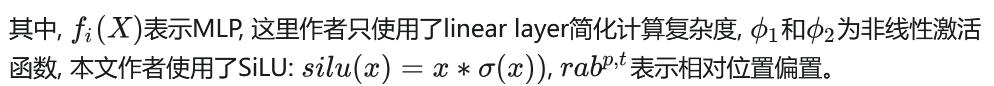
3.2 优化细节
3.2.1 Pointwise aggregated attention
- 在推荐中,与目标相关的先验数据点的数量是一个强有力的特征,表明用户偏好的强度,这在 softmax 归一化后很难捕捉到, 而这是至关重要的,因为我们需要同时预测值和序。
- 虽然softmax 激活对噪声具有鲁棒性,但它不太适合物料动态更新的流式训练。
3.2.2 提高稀疏性加速训练
3.2.3 最小化Activation内存使用
3.2.4 推理侧优化
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers
https://chunfei-he.github.io/2024/12/05/Actions-Speak-Louder-than-Words-Trillion-Parameter-Sequential-Transducers/