HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling

LLM 应用到推荐有三个问题需要评估:
- LLM预训练权重的真正价值:模型权重蕴含着世界知识,但是如何激活这些知识,只能使用文本输入吗?这也为之后使用 feature 输入埋下伏笔;
- 对推荐任务进行微调是有有必要性?直接使用 pretrain 还是说要进一步微调?
- LLM 是否可以应用在推荐系统中并呈现 scaling law?
传统推荐问题:推荐重要的是建模 user、item feature,主流方法是 ID-based,将 user、item 转为 ID 并创建对应的 embedding table,然而一般都是 embedding 参数很大而模型参数较小,这会导致以下问题:
- 严重依赖 ID feature 在冷启动时表现不好
- 模型较小难以建模复杂且多样的用户兴趣
过往 LLM 探索方向:大致分为三种:
- 利用 LLM 提供一些信息给推荐系统
- 将推荐系统转变为对话驱动的形式
- 修改 LLM 不再只是文本输入/输出,比如直接输入 ID feature 给 LLM
Hierarchical Large Language Model Architecture
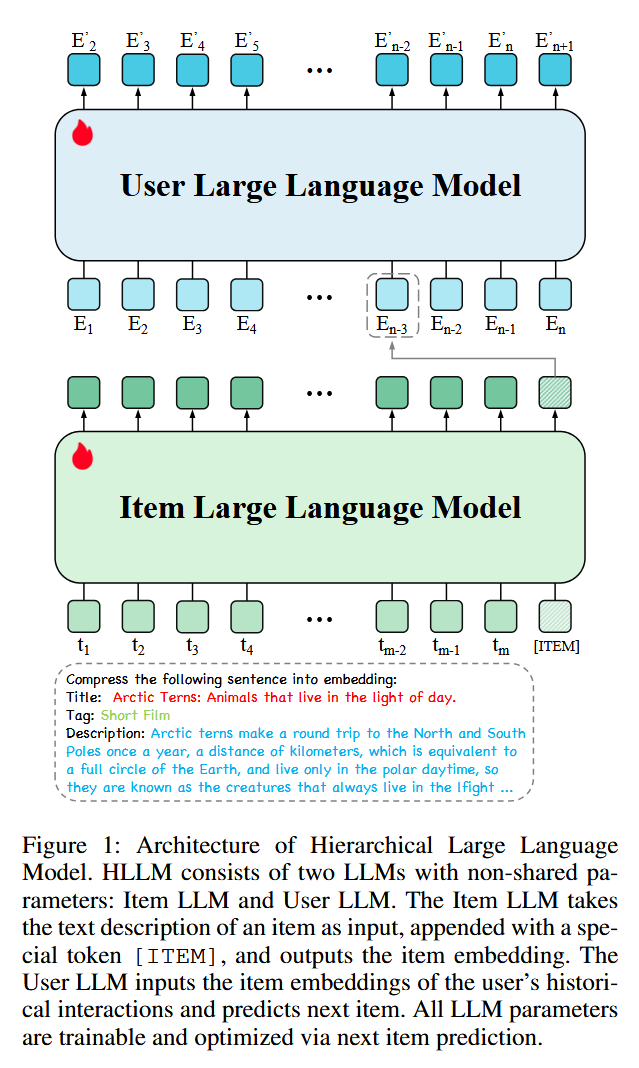
Item LLM:使用 item 的描述作为输入,包括 Title、Tag、Description,最后再加上一个特殊 token:[ITEM],特殊 token 对应输出的代表该 item 的 embedding;
User LLM:输入是用户历史交互序列,输入序列中每个 item 就来自于 Item LLM 的输出。由于输入并非文本 token,所以会去除预训练模型的 word embedding;
Training for Recommendation Objectives
生成式:
判别式: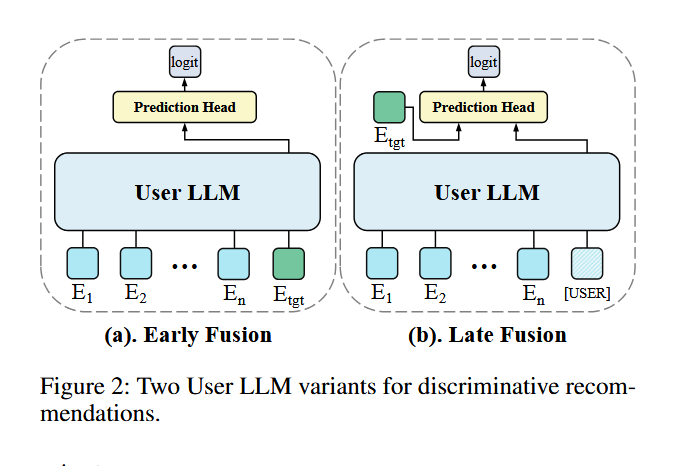


https://zhuanlan.zhihu.com/p/722159726
https://zhuanlan.zhihu.com/p/14074487300
HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
https://chunfei-he.github.io/2025/01/11/HLLM-Enhancing-Sequential-Recommendations-via-Hierarchical-Large-Language-Models-for-Item-and-User-Modeling/