OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment


前言
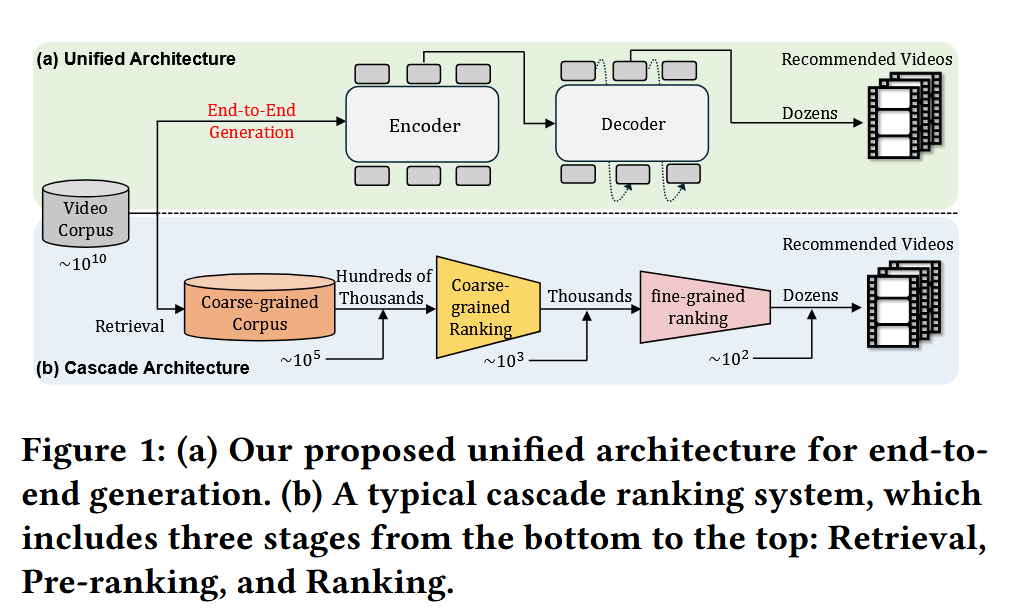
过去十多年里,推荐系统大规模应用于短视频、电商、信息流等场景。主流方案几乎都是 **多阶段级联 (cascaded)**:
- 召回(Recall):从海量库 (~10¹⁰ 级别) 中快速筛出候选。
- 粗排(Pre-ranking):进一步缩小范围。
- 精排(Ranking):用复杂模型精细打分。
这种架构的优点是 效率高,能在超大规模库里低延迟返回结果。但也存在一些 固有问题:
- 计算碎片化:大量资源浪费在通信和存储,真正算力利用率很低(训练 MFU 只有 4.6%,推理 11.2%
- 目标冲突:不同阶段、不同模型优化的目标不一致,导致上下游之间相互掣肘,整体优化困难。
- 滞后于 AI 发展:LLM/VLM 领域已经有了 Scaling law、RLHF、DPO 等成熟经验,但多阶段结构使这些技术难以直接应用到推荐中
受到 生成式信息检索 (Generative Retrieval, GR) 的启发,学界和业界开始尝试把推荐建模为 序列生成问题。
- 用 语义 ID (semantic token) 表示物品,通过 自回归生成 的方式直接产出候选列表。
- 代表工作如 TIGER、LC-Rec 等,证明了这种思路的可行性,但此前多停留在“生成 = 召回”,并没有真正统一排序阶段
为了解决上述挑战,论文提出了一种统一的端到端单阶段生成式推荐框架OneRec,包括以下三个关键设计:
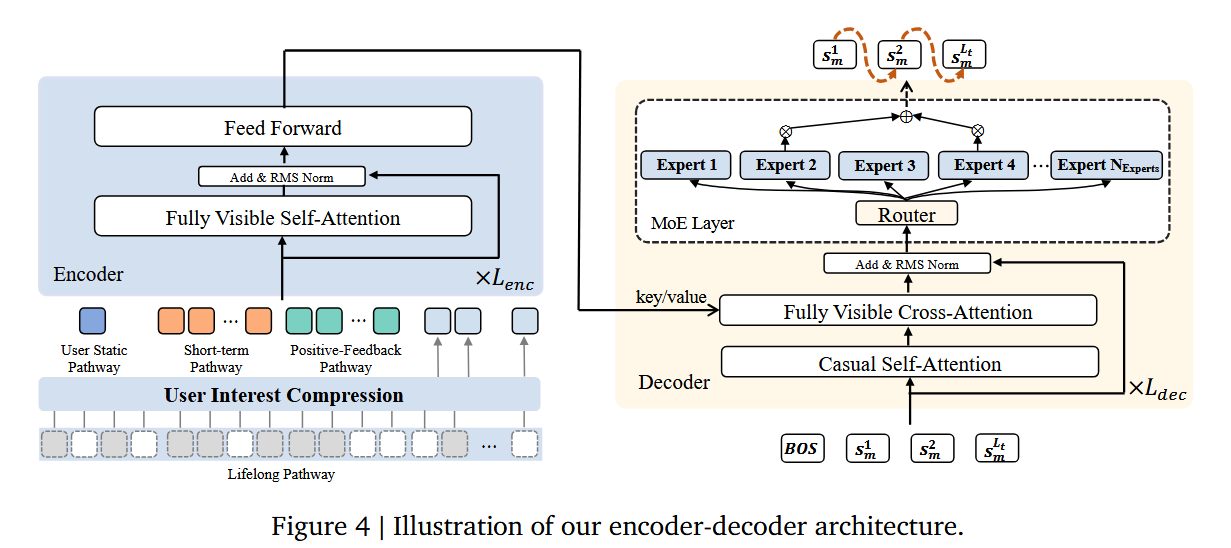
1.编码-解码结构:用于编码用户的历史行为序列,并逐步解码出用户可能感兴趣的视频。引入了稀疏专家混合模型MoE,在不显著增加计算量的前提下扩展模型容量。
2.基于会话的生成方式:与传统的“下一个物品预测”不同,提出了一种基于会话的生成方法,避免了依赖手工规则将生成结果拼接的繁琐过程。
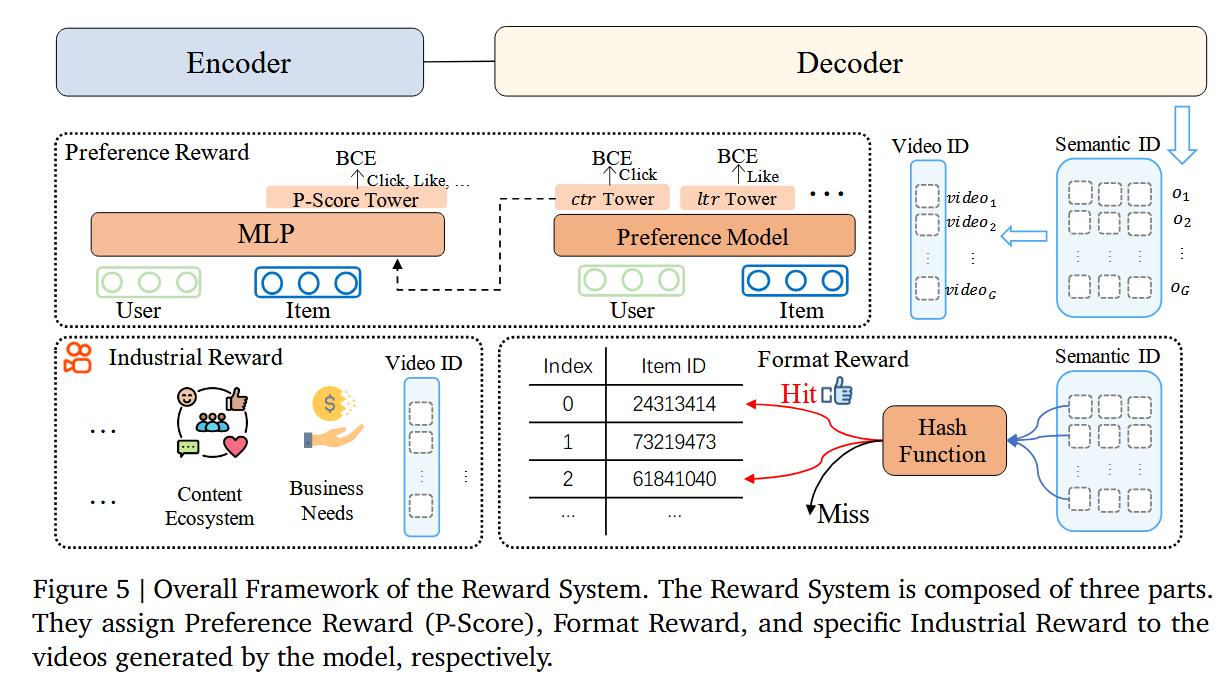
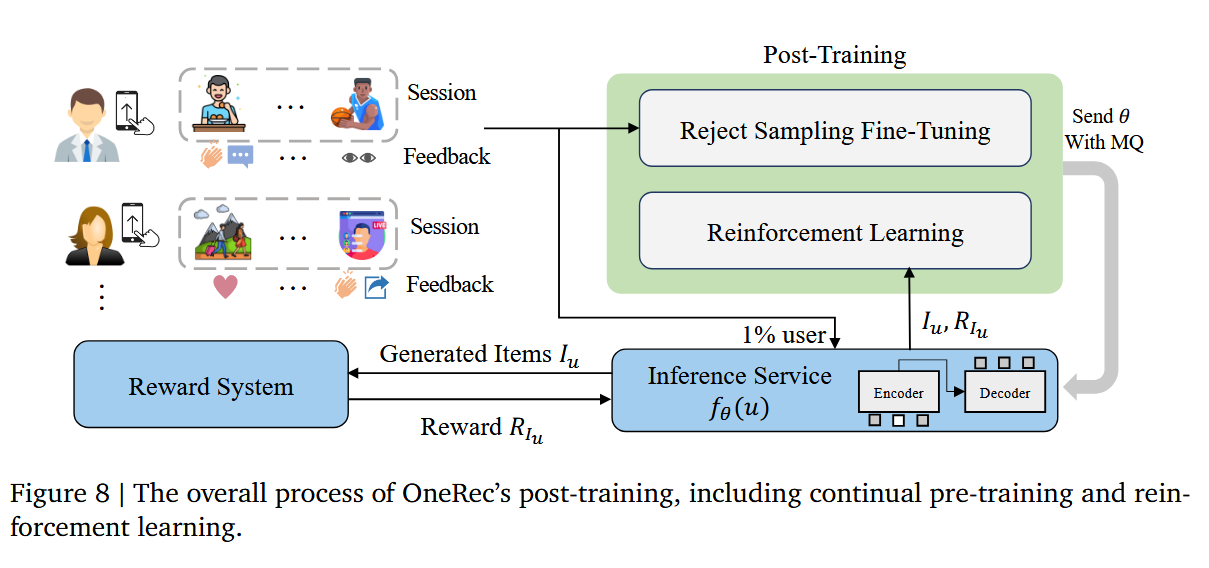
3.偏好对齐模块与直接偏好优化DPO结合:用于增强生成结果的质量,设计了一个奖励模型来模拟用户的生成行为,并根据推荐系统在线学习的特性定制了采样策略。
大量实验表明,即便只使用少量DPO样本,也能有效对齐用户兴趣偏好,并显著提升生成结果的质量。已在快手主推荐场景中部署了OneRec,最终将用户观看时长提升了**1.6%**。
Methods
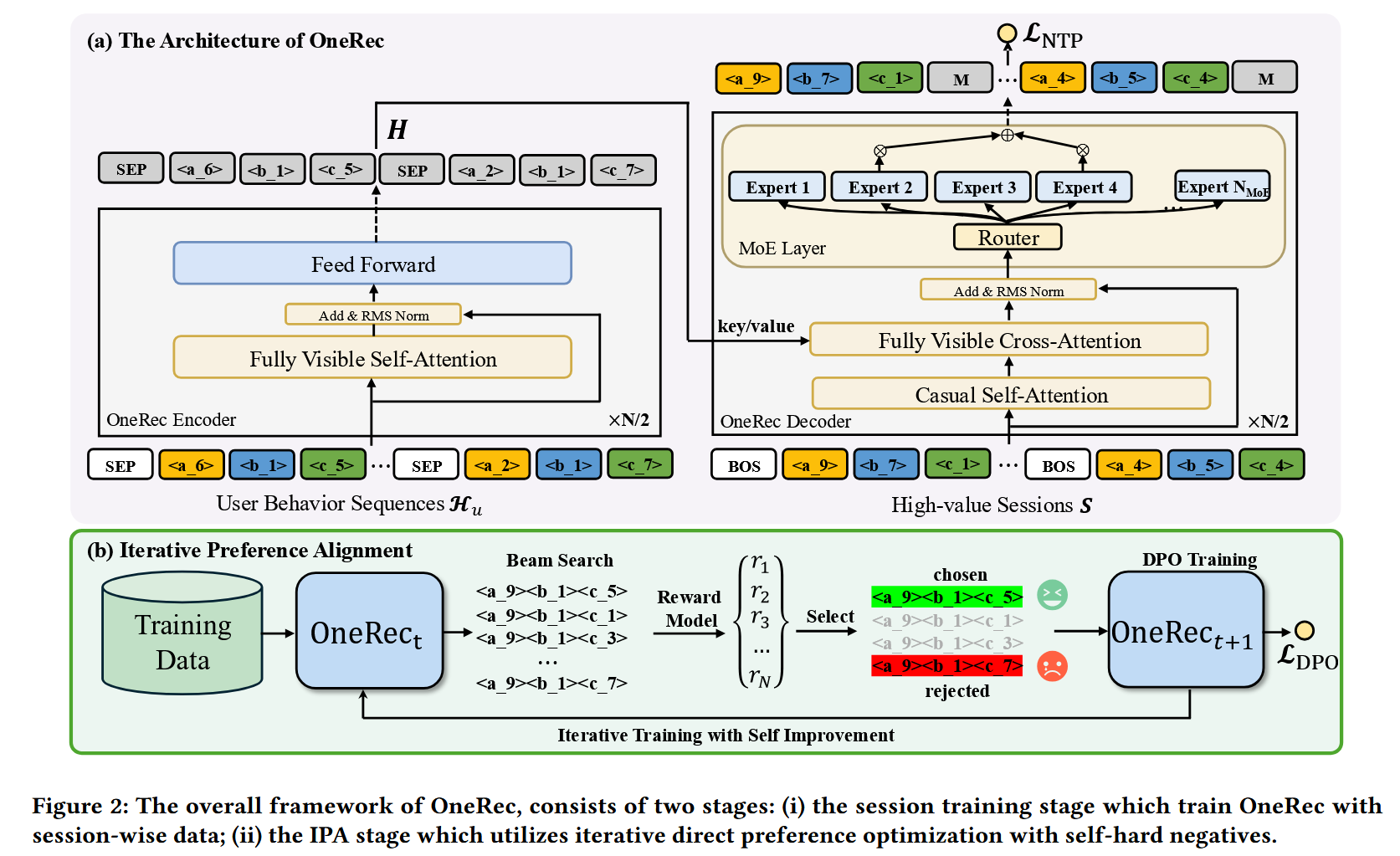
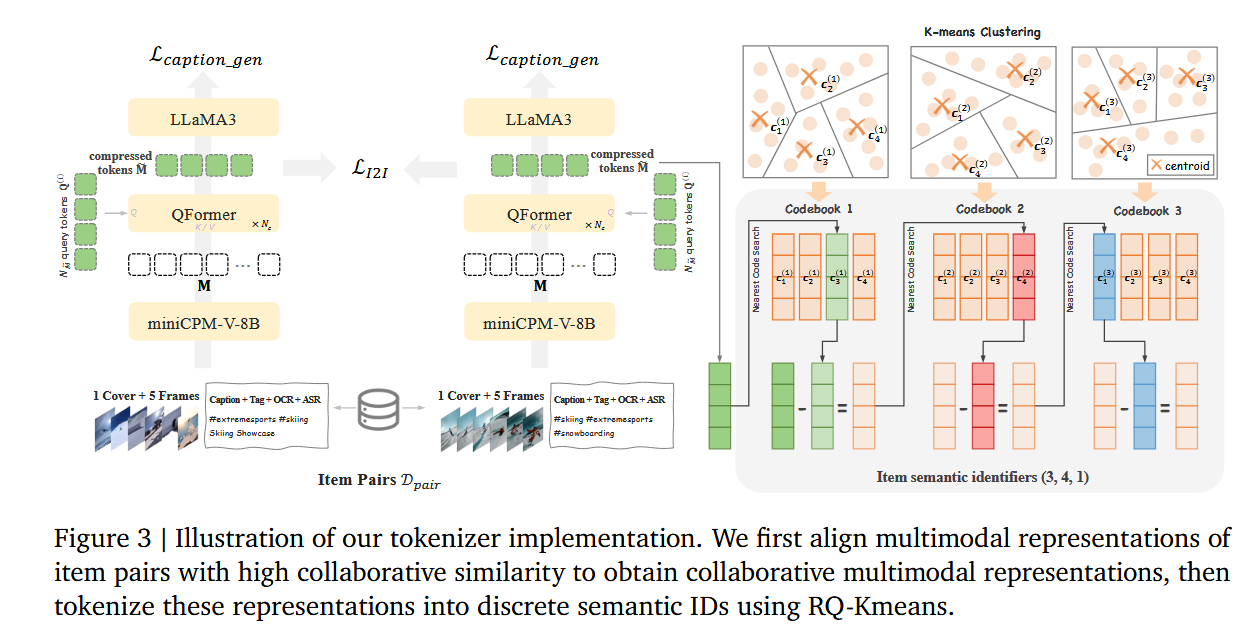
tokenization

Session-wise List Generation
Iterative Preference Alignment with RM
OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment
https://chunfei-he.github.io/2025/08/12/OneRec-Unifying-Retrieve-and-Rank-with-Generative-Recommender-and-Preference-Alignment/